
몰?.루();
코틀린 DFS, BFS 코드 본문
학부생 때는 이걸 C언어로 하다보니 DFS, BFS 구현은 둘째치더라도 인풋을 받아서 배열에 넣는 과정조차 정말 오래걸렸습니다.
근데 확실히 코틀린으로 하니까 인풋을 배열에 넣는 건 정말 쉬웠습니다. 제가 코틀린을 좋아하는 이유기도 합니다.
입력
// 입력
val inputs = """
15 16
1 2
1 8
1 9
2 3
2 7
2 5
3 4
3 6
4 5
9 10
9 15
9 13
10 11
10 12
13 12
13 14
""".trimIndent().lines()
println("============= inputs =============")
inputs.forEach { println(it) }
// 입력을 배열로 저장
val (v, e) = inputs[0].split(" ").map { it.toInt() }
val edges = Array<ArrayList<Int>>(e + 1) { ArrayList() } // 0 버림
val visited = BooleanArray(v + 1) // 0 버림
for (i in 1 .. e) {
val (a, b) = inputs[i].split(" ").map { it.toInt() }
edges[a].add(b)
edges[b].add(a)
}뭐 보통 코딩 테스트를 할 때는 readLine()으로 인풋을 받겠지만 이 코드를 컴퓨터에서 돌리는 게 아니라 안드로이드 스튜디오로 해서 앱 위에서 돌릴 분들도 있을 거 같아서 일부러 인풋을 단순한 String으로 받았습니다.
참고로 inputs는 배열입니다. 문자열이 아닙니다. 문자열을 .lines()로 줄 단위로 잘랐기 때문입니다.
인풋 제일 첫 줄은 vertex의 개수, edge의 개수입니다. 그 다음 줄부터는 edge들이 어디랑 어디가 연결되어있는지에 대한 정보들입니다.
따라서 이 예제엔 15개의 노드(혹은 vertex), 16개의 엣지가 있는 그래프입니다.

inputs.forEach를 통해 인풋 배열을 출력했습니다.

// 입력을 배열로 저장
이라고 주석이 적힌 부분 아래는 실제로 인풋을 각 변수와 배열에 넣는 부분입니다.
v는 노드의 개수인 15
e는 엣지의 개수인 16
edges엔 각 엣지들이 어디랑 어디가 연결되어있는지 들어있습니다. (edges[3]의 ArrayList에 [4, 5]가 있다는 말 == 3은 4, 5와 연결되어있다는 말)
visited는 방문한 노드인지 아닌지를 적어두는 배열입니다. (중복 방문 피하기 위해서)
노드가 1~v까지이기 때문에 0이 포함되지 않으므로 edges와 visited는 일부러 크기는 v+1, e+1로 잡았습니다. [0]번째 원소는 필요 없으니 사용하지 않을 겁니다.
DFS
본격적으로 dfs를 구현해봅시다.
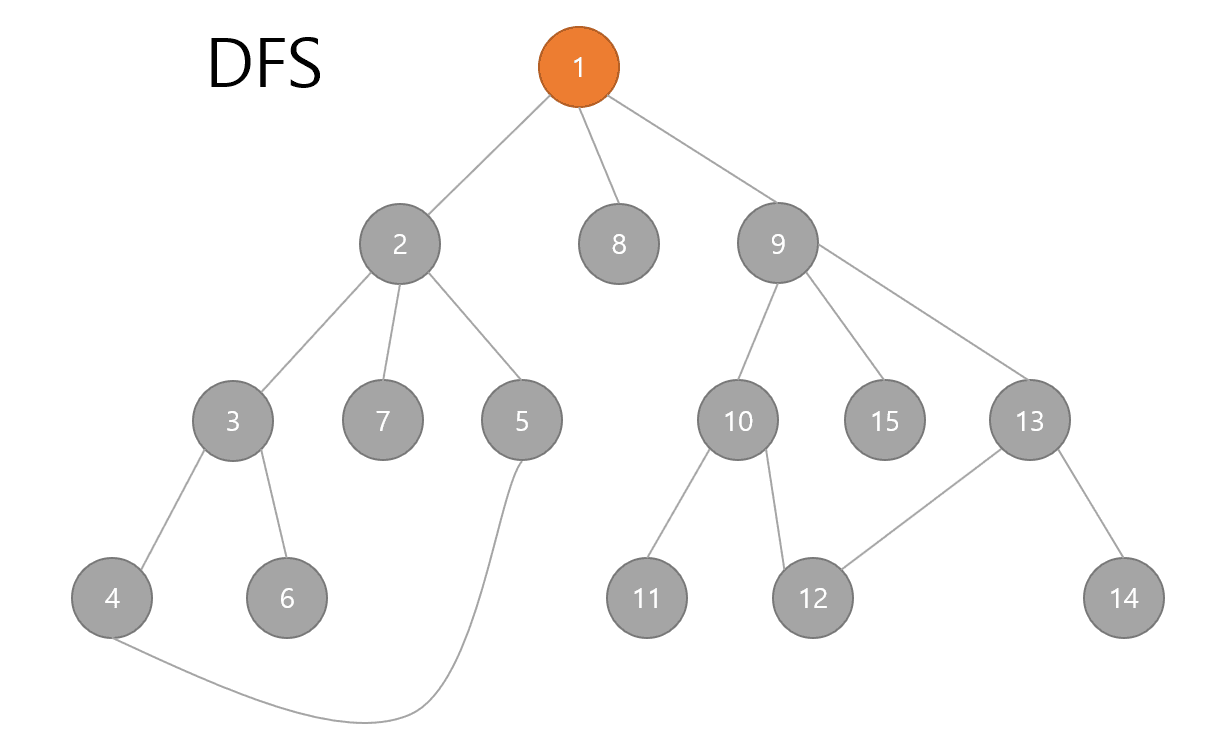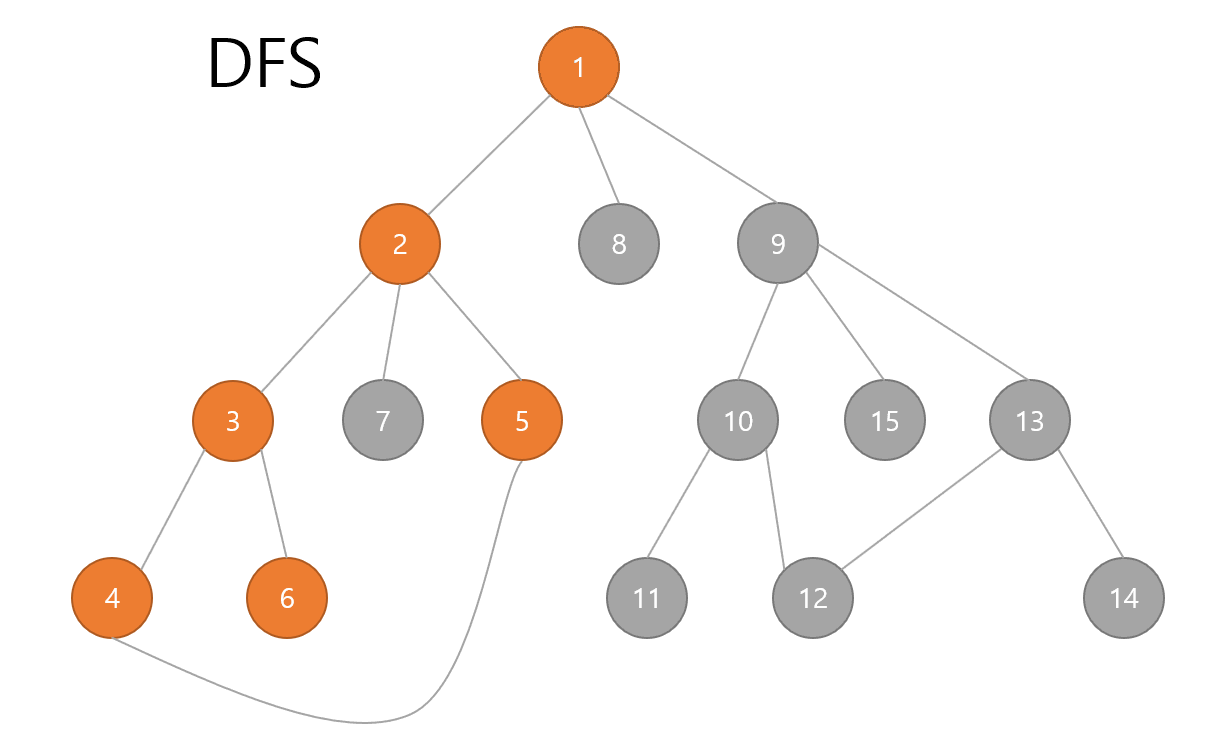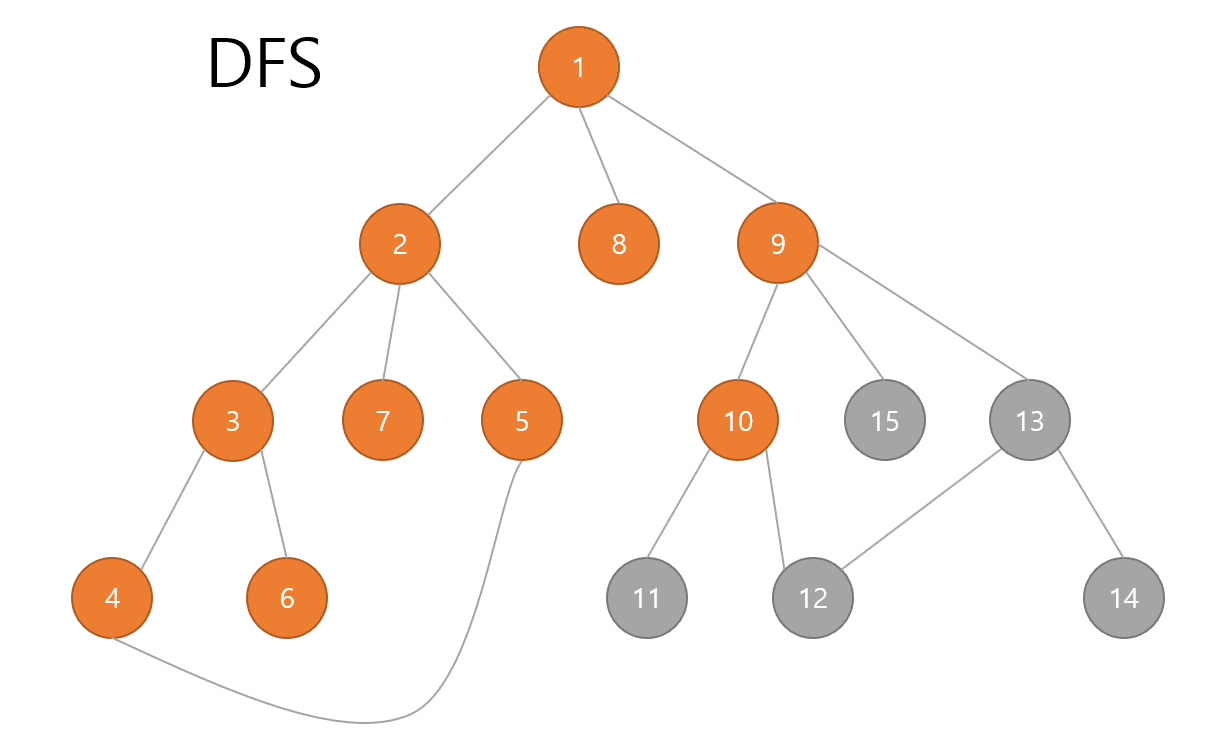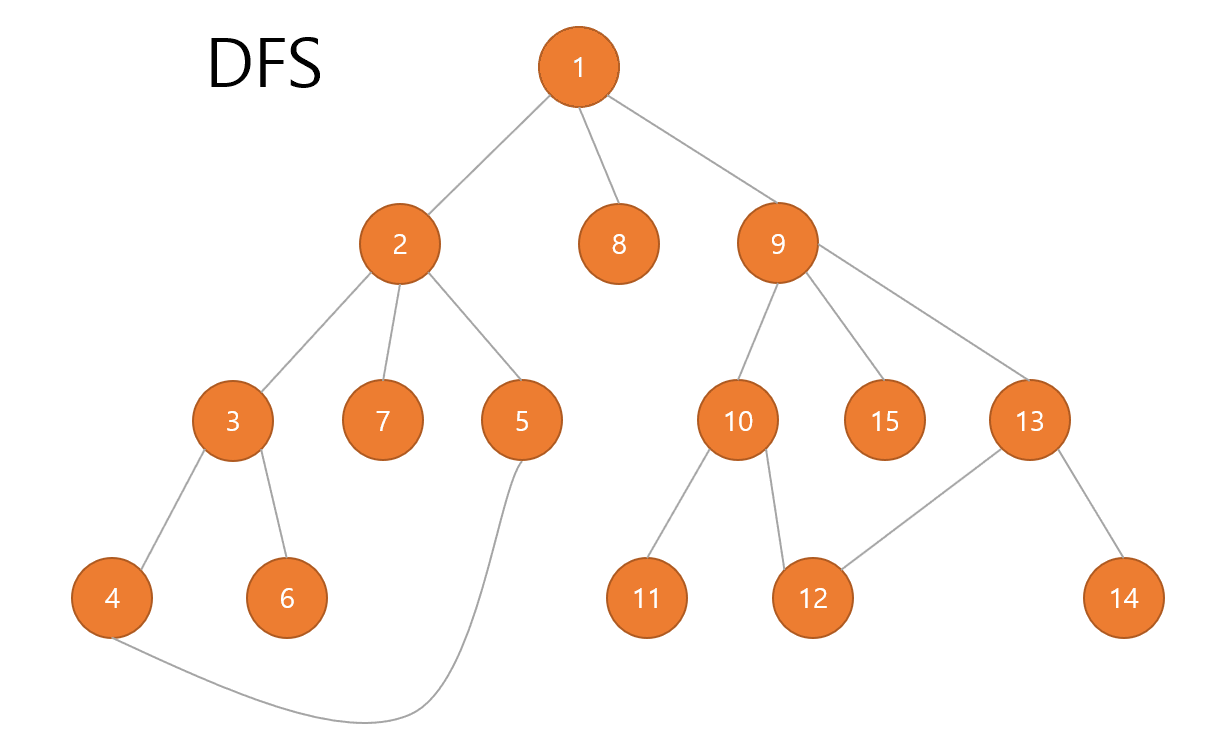
DFS는 스택이나 재귀함수를 통해서 구현이 가능합니다.
재귀 함수가 구현하기 쉬워서 보통 재귀함수를 통해서 구현합니다.
// dfs
println("============= dfs =============")
fun dfs(index: Int) {
visited[index] = true
println(index)
// 구현
for (next in edges[index]) {
if (!visited[next]) {
dfs(next)
}
}
}
dfs(1)함수 선언이 위에 있어서 그런데 먼저 제일 아래에 있는 dfs(1)부터 코드를 보셔야합니다.
- 1번 노드를 방문하였다 표시하고 1을 출력합니다
- for문으로 들어옵니다.
- 1번과 가장 처음 연결되어있는 2번 노드가 next가 됩니다.
- visited[2]는 false이므로 dfs(2) 합니다. dfs(1)의 for문은 dfs(2)가 끝날 때까지 기다립니다.
- dfs(2)를 통해 2번 노드를 방문했다고 표시하고 2를 출력합니다.
- 2번 노드와 연결된 노드 중 첫 번째인 1번 노드는 visited[1] == true니까 패스합니다.
- 2번 노드와 연결된 노드 중 두 번째인 3번 노드는 visited[3] == false니까 dfs(3) 합니다. dfs(2)의 for문은 dfs(3)이 끝날 때까지 멈춰있게 됩니다.
- ... 이런 식으로 방문하지 않은 모든 노드를 깊이 우선으로 1번씩만 탐색합니다.
그 결과 다음과 같습니다.

일부러 제가 노드를 dfs 기준 순서대로 맞춰놓았기 때문에 1~15가 순서대로 출력되는 것을 알 수 있습니다.
위 그래프 그림에서 직접 손으로 순서대로 따라가보면 맞다는 것을 알 수 있습니다.
BFS
다음은 BFS입니다.
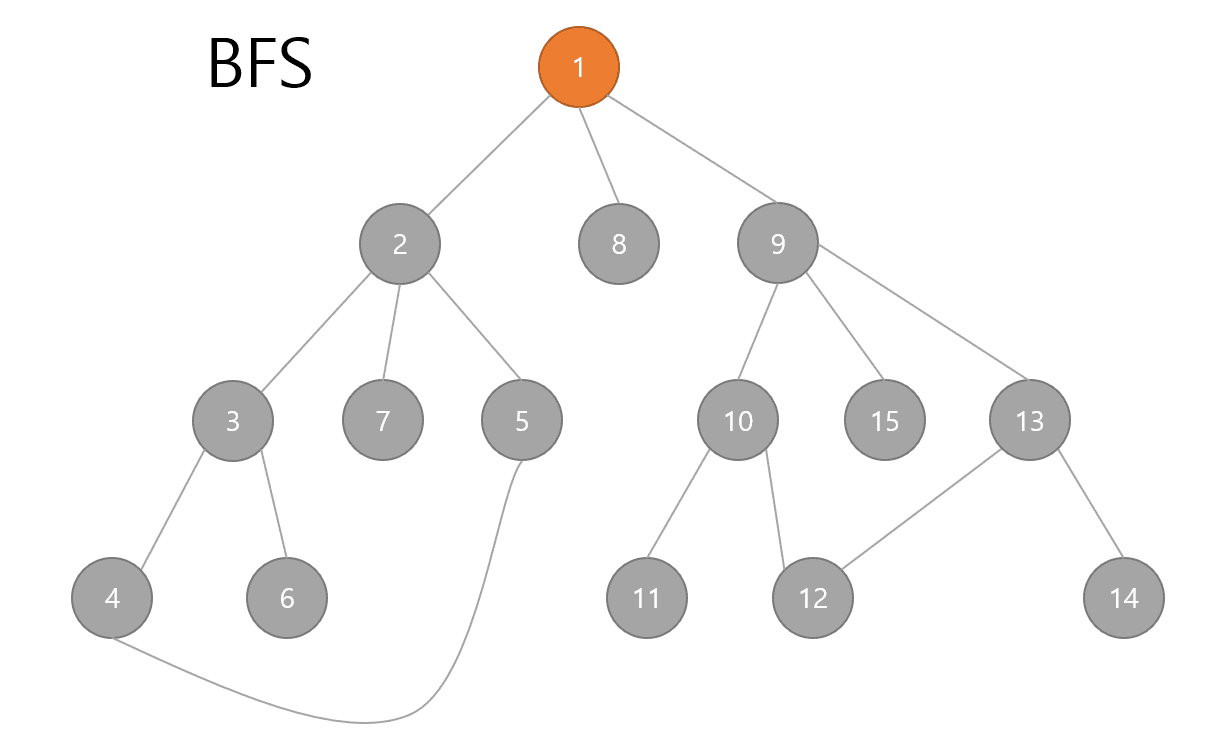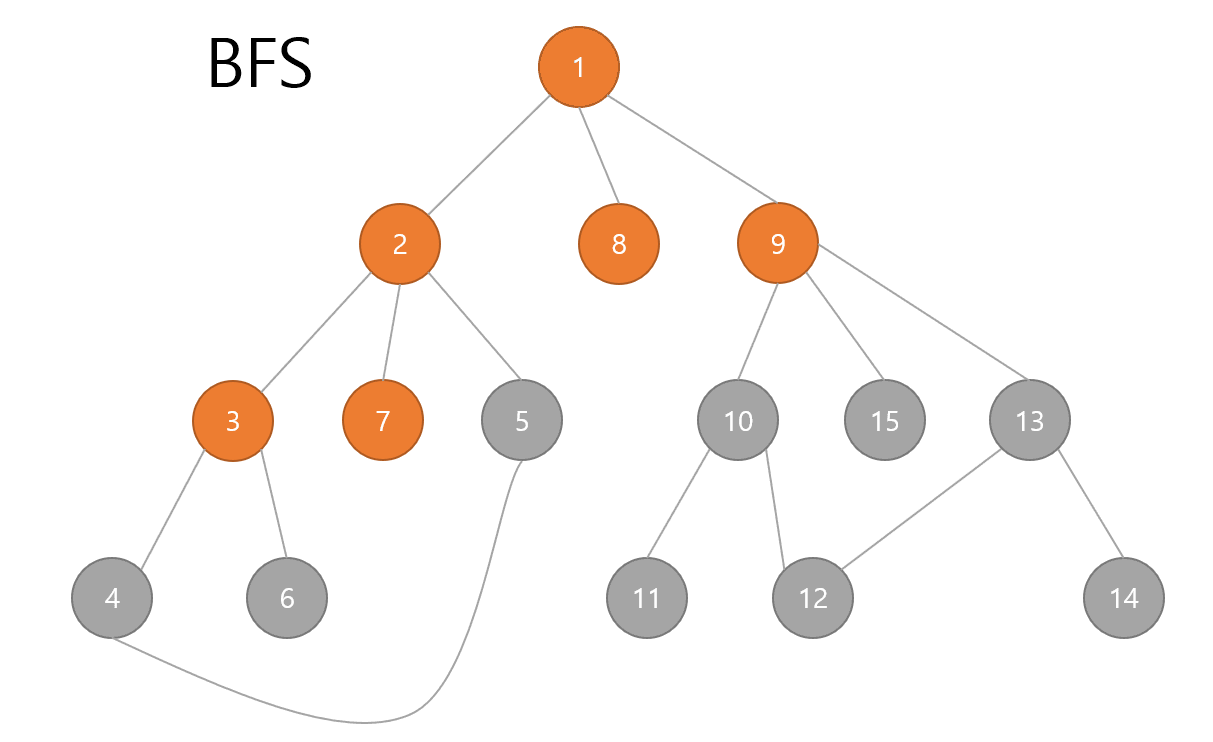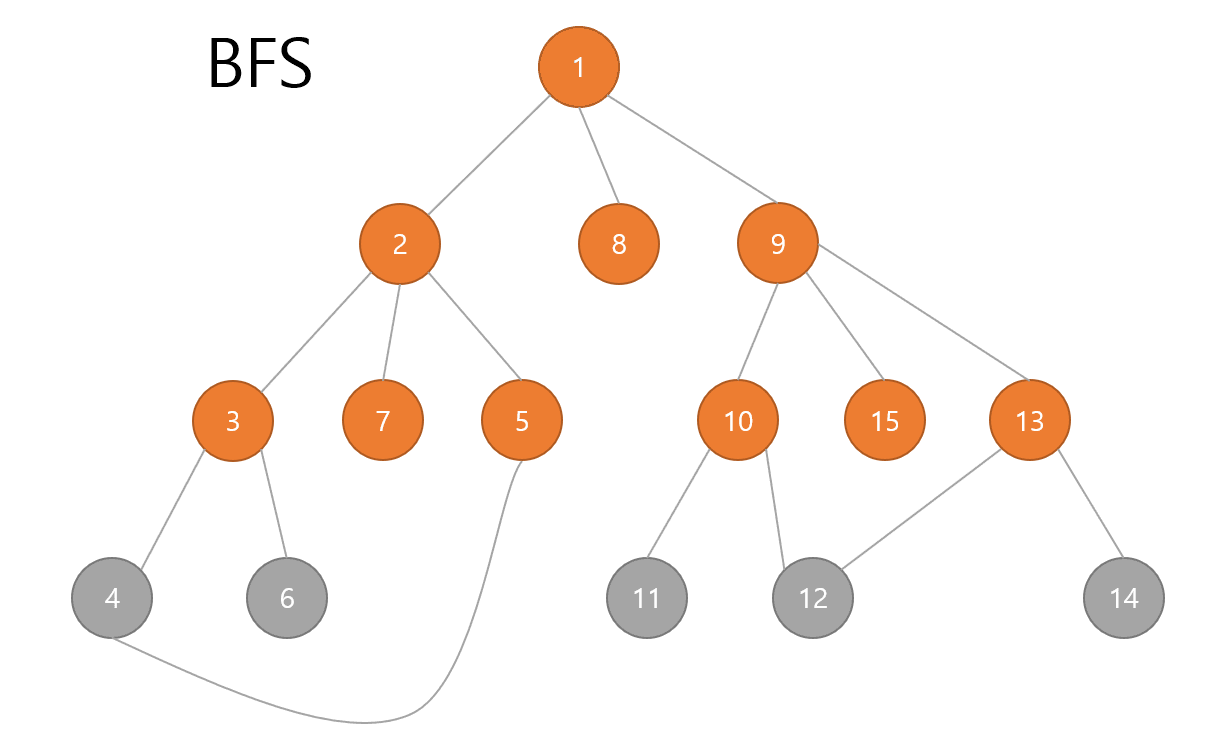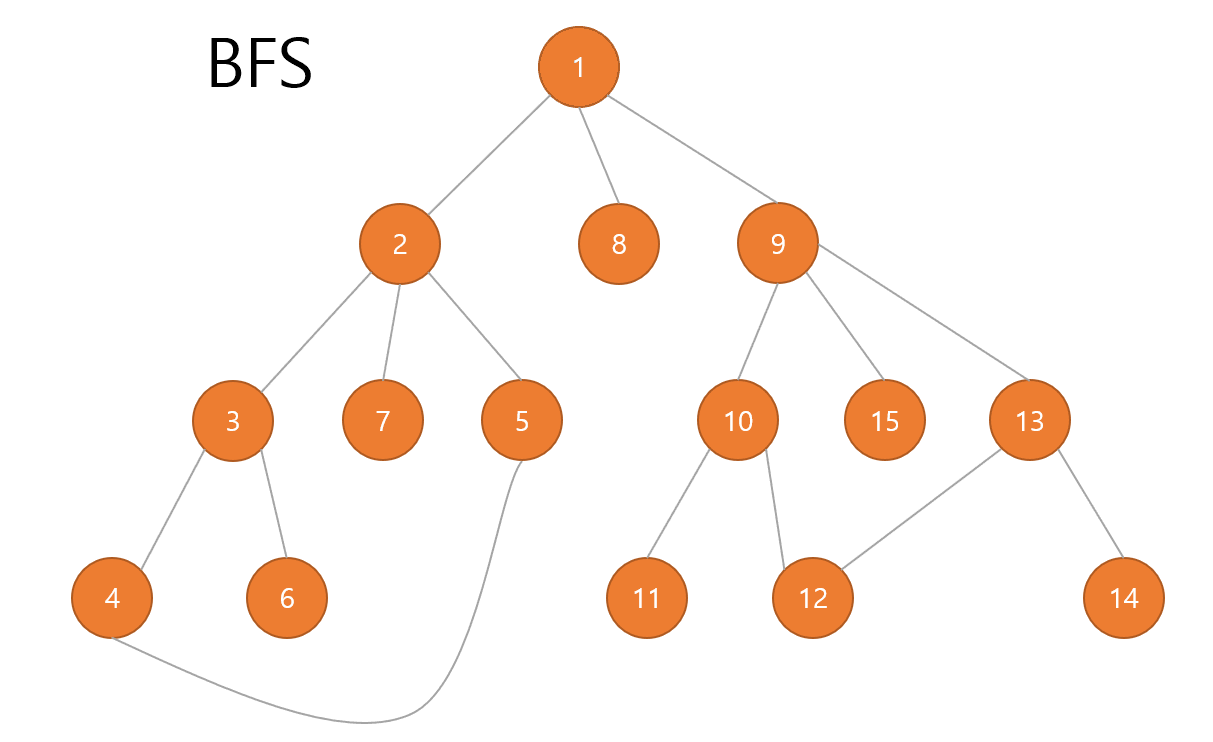
쉽게 말해 위쪽부터 가로로 탐색해 나가면 됩니다.
BFS는 큐를 통해서 구현합니다. 큐라는 것은 먼저 들어온 애가 나갈 때도 제일 먼저 나가는 방식(선입선출, FIFO)입니다.
코틀린에서는 Java의 LinkedList를 이용해서 Queue처럼 사용할 수 있습니다.
C언어로는 LinkedList를 구현하는 것부터가 고역이었는데 참 편리한 세상입니다. 물론 LinkedList 정도는 코틀린급이 아니라 C++ 정도만 되도 기본적으로 제공합니다. 언제나 퓨어 C가 문제지...
Q) 왜 ArrayList를 쓰지 않고 LinkedList를 쓰나요?
A) 물론 ArrayList를 큐로 사용할 수도 있습니다. 원소를 넣을 땐 add()로, 뺄 때는 removeFirst()로 빼내면 완벽하게 선입선출이니까 큐로 사용할 수 있습니다. 하지만 문제는 ArrayList가 첫 번째 원소를 제거하는 방식입니다. ArrayList는 첫 번째 원소를 제거하면, 빈 자리를 채우기 위해 두 번째부터 마지막 원소를 전부 앞으로 한 칸씩 복사합니다. 즉, ArrayList는 제일 앞의 원소를 뺄 때마다 O(n)의 시간 복잡도가 발생합니다.
LinkedList는 반면에 첫 원소를 빼려면 그냥 header의 포인터를 두 번째 원소로 연결만 시키면 되는 구조이기 때문에 LinkedList는 O(1) 시간 복잡도만에 첫 원소를 제거하는 게 가능합니다.
따라서 선입선출 방식으로 쓰기 위해서는 LinkedList를 사용하는 것이 효율적입니다.
import java.util.LinkedList
// bfs
println("============= bfs =============")
val queue = LinkedList<Int>()
fun bfs(start: Int) {
queue.add(start)
visited[start] = true
while (queue.isNotEmpty()) {
val head = queue.poll() // 첫 원소 반환 후 remove
println(head)
for (next in edges[head]) {
if (!visited[next]) {
visited[next] = true
queue.add(next)
}
}
}
}
bfs(1)마찬가지로 bfs(1)으로 시작합니다.
다만 bfs에서 파라미터 이름은 아까와는 달리 index가 아니라 start로 지었습니다. dfs에서는 재귀 함수를 통해서 각 노드 마다 dfs를 호출하지만 bfs는 제일 처음 딱 1번만 호출하기 때문에 파라미터를 start로 지었습니다.
뭐, 물론 파라미터 이름을 index로 한다고 해서 전혀 문제는 없긴 하지만 직관적이지 못하니까요.
bfs에 처음 들어오면 일단 1번을 큐에 집어넣고, visited도 true로 만들어줍니다.
그 다음 while문을 통해서 큐가 빌 때까지 다음 작업을 반복합니다.
- 큐에서 가장 처음 원소를 꺼냅니다. (보통 C언어 큐에서는 pop이라는 용어를 쓰는데 코틀린(자바)에서는 poll입니다.)
- 꺼낸 원소 번호를 출력합니다.
- 꺼낸 원소와 연결된 노드들 중에서 방문하지 않은 노드들을 큐에 순서대로 집어넣습니다. 그러면서 동시에 visited를 true로 만듭니다.
- 위의 과정을 큐가 빌 때까지 반복합니다.
그 결과 다음과 같습니다.
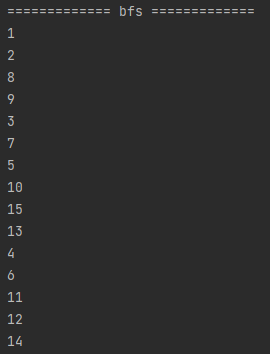
정리
DFS는 재귀함수와 for문으로 구현합니다.
BFS는 큐(Kotlin에서는 LinkedList)와 while+for문으로 구현합니다.
뭐 물론 for이 결국 while이고 while이 결국 for니까 dfs를 while로 구현할 수도 있고 bfs를 for 2개로 구현할 수도 있긴합니다만 dfs는 for로, bfs는 while+for로 구현 하는 게 이해도 쉽고 코드도 간결하고 깔끔합니다.
전체 코드
import java.util.LinkedList
fun main () {
// 입력
val inputs = """
15 16
1 2
1 8
1 9
2 3
2 7
2 5
3 4
3 6
4 5
9 10
9 15
9 13
10 11
10 12
13 12
13 14
""".trimIndent().lines()
println("============= inputs =============")
inputs.forEach { println(it) }
// 입력을 배열로 저장
val (v, e) = inputs[0].split(" ").map { it.toInt() }
val edges = Array<ArrayList<Int>>(e + 1) { ArrayList() } // 0 버림
val visited = BooleanArray(v + 1) // 0 버림
for (i in 1 .. e) {
val (a, b) = inputs[i].split(" ").map { it.toInt() }
edges[a].add(b)
edges[b].add(a)
}
// dfs
println("============= dfs =============")
fun dfs(index: Int) {
visited[index] = true
println(index)
// 구현
for (next in edges[index]) {
if (!visited[next]) {
dfs(next)
}
}
}
dfs(1)
visited.fill(false)
// bfs
println("============= bfs =============")
val queue = LinkedList<Int>()
fun bfs(start: Int) {
queue.add(start)
visited[start] = true
while (queue.isNotEmpty()) {
val head = queue.poll() // 첫 원소 반환 후 remove
println(head)
for (next in edges[head]) {
if (!visited[next]) {
visited[next] = true
queue.add(next)
}
}
}
}
bfs(1)
}위에서 설명 안 한 부분이라면 dfs와 bfs 사이에 있는 visited.fill(false) 정도?
dfs하고 나면 visited가 전부 true가 되어있는 상태니까 다시 전부 false로 만들어줘야 bfs가 제대로 동작합니다.
배열 원소를 전부 false로 바꾸는데 프로그래머가 직접 for문 돌릴 필요도 없이 함수 하나로 빠르게 구현 가능하다니 참으로 편리한 언어인 것 같습니다.
BFS 구현시 주의점
 |
 |
| 좋은 코드 | 나쁜 코드 |
똑같아 보이지만 자세히 보면 visited를 true로 설정하는 부분이 다릅니다.
왼쪽 코드는 visited = true하는 곳이 2곳 있습니다. 함수 시작하자마자 한 번, for문 안에서 1번 입니다.
오른쪽 코드는 while 만에서 1번 visited = true로 만듭니다.
어라? 오른쪽 코드가 1줄 더 적네? 그리고 상식적으로 생각하기에도 노드를 poll 했을 때가 해당 노드를 방문한 것이니까 poll 다음에 visited를 true로 만드는 오른쪽 코드가 더 좋은 게 아닌가?라고 생각할 수 있습니다.
하지만 이렇게 하면 문제가 있습니다.
여기서 12번 노드를 잘 보면 12번 노드는 10번 노드의 자식임과 동시에 13번 노드의 자식이기도 합니다.
그래서 10번 노드를 검사할 때 10번 노드의 자식인 11, 12가 큐에 들어갑니다.
하지만 아까 그 안 좋은 코드대로면 큐에는 12번이 들어가있지만 visited[12] == false인 상태입니다.
그 상태에서 13번 노드를 검사하는데 13번 노드에도 자식으로 12번이 있습니다!
근데 심지어 visited[12]를 검사해봤더니 false네요? 그럼 12번을 또 queue에다가 집어넣어버리게 됩니다.
따라서 출력할 때 12번이 2번 출력되는 참사가 일어납니다.
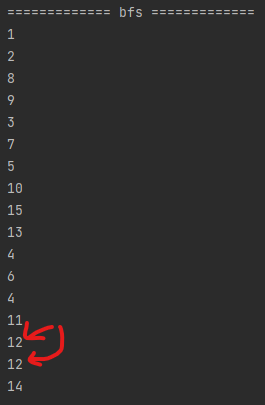
따라서 bfs할 때 "큐에서 해당 노드를 꺼내는 시점이 방문하는 거니까 그때 visited를 true로 만들어주는 게 맞지 않나?"라는 생각은 잘못된 결과를 초래합니다. queue에 넣는 순간에 visited를 true로 만들어주는 게 맞습니다.
'프로그래밍 > 안드로이드, 코틀린' 카테고리의 다른 글
| 백준 1920번 코틀린 (0) | 2022.03.15 |
|---|---|
| 백준 1753번 최단경로 (다익스트라) 문제 코틀린 코드 (0) | 2022.03.11 |
| 코틀린 String에서 특정 문자 개수 count (혹은 Int형 특정 숫자 개수) (0) | 2022.02.24 |
| 코틀린 IntArray와 Array<Int> 차이 (0) | 2022.02.24 |
| 코틀린 filter, map 사용법 (0) | 2022.02.23 |

