
몰?.루();
백준 1753번 최단경로 (다익스트라) 문제 코틀린 코드 본문
구글에 검색해봤는데 이 문제 코틀린 코드는 정말 찾아보기 힘들더라구요.
특히 그나마 몇 개 있는 코드들도 Java스러운 느낌이 강하게 드는 코드라 코틀린스럽게 짜본 코드를 공유 및 개인 저장 차원에서 올려봅니다.
import java.util.PriorityQueue
const val INF = 1000000
fun main() {
// 1. 인풋
val (v, e) = readLine()!!.split(" ").map { it.toInt() }
val start = readLine()!!.toInt()
val edges = Array(v + 1) { ArrayList<Pair<Int, Int>>() }
val dist = IntArray(v + 1) { INF } // start에서 (여기저기 거쳐서) i에 도착할 때 최소 비용, INF로 초기화
repeat(e) {
val (a, b, w) = readLine()!!.split(" ").map { it.toInt() }
edges[a].add(Pair(b, w))
}
// 2. 다익스트라 알고리즘 (우선순위 큐 사용)
fun dijkstra() {
dist[start] = 0 // 문제에 start에서 start로 도착하는 경우는 비용이 0이라고 정함
val queue = PriorityQueue<Pair<Int, Int>> { a, b -> a.second - b.second } // ex) 큐에 2, 3번 노드가 순서대로 들어가더라도 dist[2]가 dist[3]보다 더 작다면 3이 큐의 앞쪽에 추가되고 2가 뒤로 간다
queue.add(Pair(start, 0))
while (queue.isNotEmpty()) {
val head = queue.poll()
if (head.second > dist[head.first]) continue // 큐에 (2, 99)가 먼저 들어왔는데 비용이 높다보니 큐 우선 순위에서 자꾸 밀리다가 다른 곳에서 2번 노드 dist를 5로 갱신하고 (2, 5)를 큐에 넣으면 (2, 99)보다 먼저 실행됨. 나중에 큐가 차츰 줄어들어 (2, 99) 차례가 왔을 때 이미 (2, 5) 때 2번 노드 이웃에 대해 검사를 완료했으므로 굳이 for문을 돌 필요가 없음
for (next in edges[head.first]) { // head와 연결된 노드들
val nextNum = next.first // head와 연결된 노드의 번호
val costOfHeadToNext = next.second // head에서 next로 갈 때 비용 (start에서 next까지 가는 비용과는 다르다! dist[nextNum]과는!)
// 지금까지 알아낸 start에서 nextNum으로 가는 최저 비용보다도 start에서 head 거쳤다가 next로 오는 게 더 빠를 때
if (dist[nextNum] > dist[head.first] + costOfHeadToNext) {
dist[nextNum] = dist[head.first] + costOfHeadToNext
queue.add(Pair(nextNum, dist[nextNum]))
}
}
}
}
dijkstra()
// 3. 출력
for (i in 1 .. v) {
if (dist[i] >= INF) println("INF") else println(dist[i])
}
}
뭐 일반적인 우선 순위 큐를 사용한 다익스트라 알고리즘 자바 코드와 크게 다르지 않지만 PriorityQueue에 넣는 게 Pair라는 점이 다릅니다.
코틀린의 Pair는 참으로 편리한 거 같습니다. 딱 2개씩 쌍으로 이뤄서 배열에 넣어야하는 경우가 많은데 그럴 때 Pair만한 게 없거든요. 자바(구버전) 같은 언어라면 구조체를 만들거나 길이 2짜리 배열을 써야하는데 코틀린은 그럴 필요가 없습니다.
다만 한 가지 문제는 Pair 자체엔 compareTo 함수가 없기 때문에 Pair끼리 뭐가 더 높은지 낮은지 비교가 불가능합니다. 애초에 Pair의 first끼리 비교할지 second끼리 비교할지 알 수 없으니 기본적으로 제공하지 않는 게 당연합니다. 심지어 Pair에 들어가 있는게 Int형 같은 게 아니라 MyClass 이런 것일 수도 있으니까요.
그래서 PriorityQueue에 Pair를 사용하면 우선순위를 파악할 수가 없으니 문제가 발생합니다.
따라서 직접 우선순위를 어떤 걸로 할 지 알려줘야합니다. 람다식을 통해서 Pair의 우선순위를 어떻게 할 지 알려줬습니다.
val queue = PriorityQueue<Pair<Int, Int>> { a, b -> a.second - b.second }a와 b는 큐에 들어가있는 2개의 Pair를 나타냅니다.
람다식의 결과 값이 낮으면 a가 우선순위가 높다는 뜻입니다.
저희는 first가 아니라 second가 낮을 수록 높은 우선순위를 가지게 할 것이기 때문에 (== cost가 낮을 수록 높은 순위)
b.second - a.second가 아니라 a.second - b.second로 정해주었습니다.
즉, 큐에 (1, 3)과 (10, 1)이 있으면 second가 작은 (10, 1)이 큐의 제일 앞으로 갑니다.
또한 제가 다른 분들의 다익스트라 알고리즘 코드를 보다가 정말 의아했던 게 있었는데
28번째 줄 if문
if (head.second > dist[head.first]) continue은 없어도 정답으로 잘 처리되었습니다. 그래서 처음엔 다른 곳 이 코드에서 봤을 때 이거 왜 있는 거지? 이 생각을 했습니다.
37번 줄을 보면
queue.add(Pair(nextNum, dist[nextNum]))head의 second가 결국 dist[head.first]랑 똑같습니다.
그럼 28번째 줄은
if (head.second > dist[head.first]) continue // head.second == dist[head.first] 아닌가??똑같은 값끼리 대소 비교를 하고 있는 이상한 코드라고 생각 했거든요.
head.second가 결국 dist[head.first]인데 >로 비교하고 있다니 이상하지 않나요?
그런데 다음 경우를 생각해보니 왜인지 알겠더라구요.
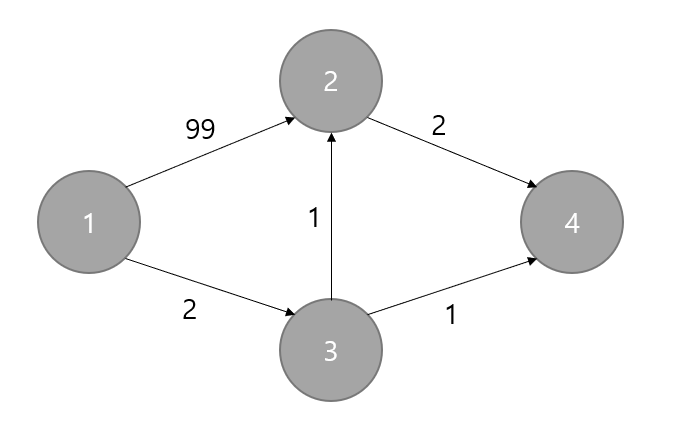
이 경우를 생각해보면 다음과 같이 됩니다. (이해를 돕기 위해 PriorityQueue를 트리 구조가 아니라 선형 배열 구조라고 가정 했습니다.)

제일 처음엔 큐에 (1, 0)을 넣고 다익스트라를 시작합니다.
1은 시작 노드 번호이고 0은 dist[1]이 0이니까 Pair(1, 0)이 큐에 제일 처음 들어간 것입니다.

큐에서 1을 빼고 1번 노드와 인접한 애들을 검사하기 시작하겠죠.
1번 노드 자식인 2번 노드가 next가 됩니다.

dist[2]를 INF에서 99로 새롭게 갱신합니다.
갱신했으니 큐에 Pair(2, 99)를 넣습니다.
아직 1번 노드 자식들에 대한 검사가 덜 끝났죠. 3번 노드가 남아있습니다.
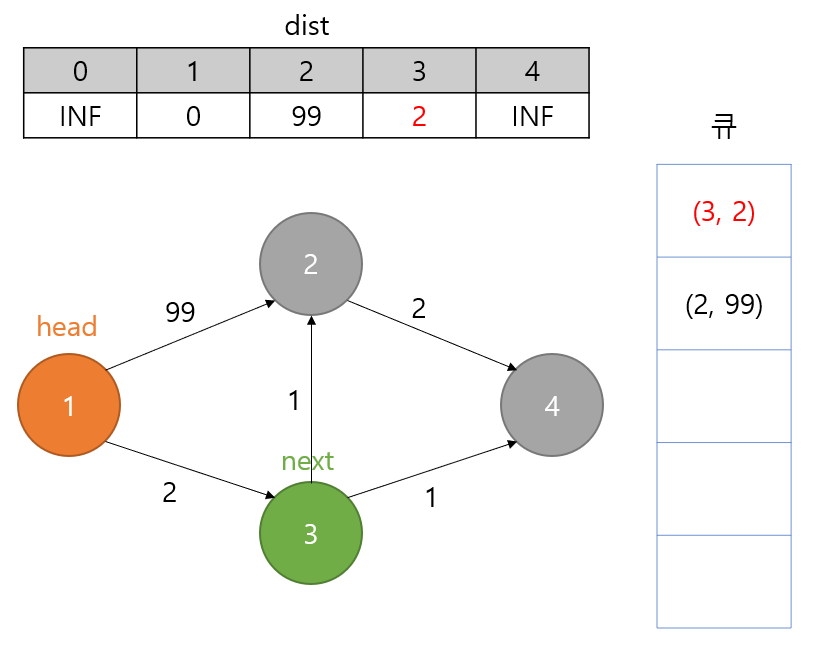
dist[3]을 2로 갱신합니다.
갱신했으니 큐에 Pair(3, 2)를 추가합니다.
그런데 기존에 있던 (2, 99)보다 (3, 2)의 second가 더 낮으니 더 우선순위가 높으므로 (3, 2)가 제일 앞으로 옵니다.
1의 자식 노드가 더 이상 없습니다.
큐에서 하나를 뽑습니다.

큐에서 (3, 2)가 빠져나와서 head는 3이 됩니다.
이제 3번 노드의 자식 노드들에 대해서 검사를 합니다.
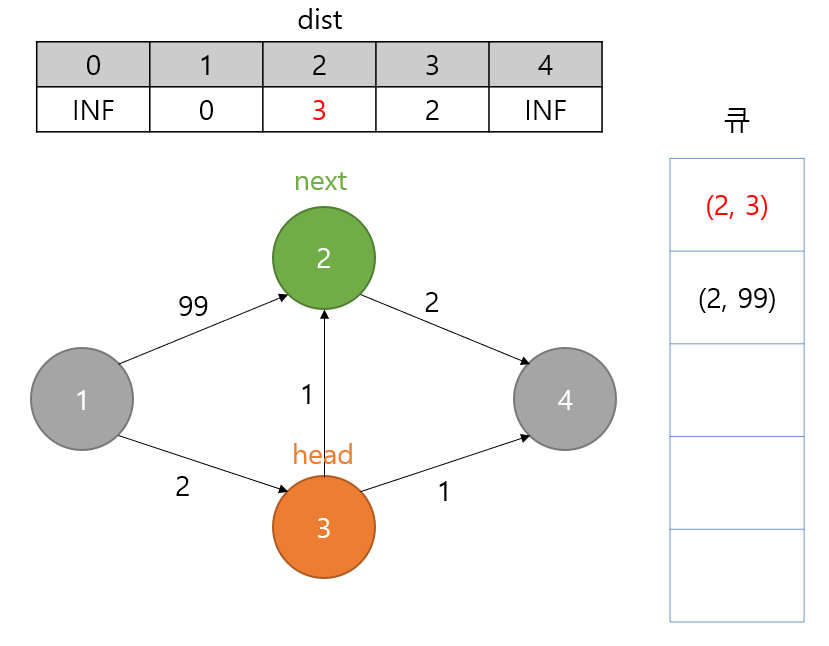
자식 노드인 2번 노드에 대해 검사를 합니다.
기존 dist[2]가 99였는데 dist[3]에서 1을 더한 것, 즉, 3번을 거쳐서 2번으로 가는 게 비용이 훨씬 저렴합니다.
dist[2]를 3으로 갱신합니다.
갱신했기 때문에 Pair(2, 3)을 큐에 집어넣습니다.
여기서 문제가 발생합니다.
큐엔 이미 아까 1번 노드의 자식 검사할 때 넣은 (2, 99)가 있습니다.
근데 우선 순위가 높은 3번 노드가 새치기 하면서 3번 노드도 자식으로 2번 노드가 있으니까 (2, 3)을 큐에 넣었죠.
그럼 (2, 3)이 head가 되어서 큐에서 나왔을 때, 이미 2번의 자식 노드에 대한 검사는 최신화가 되어있는 상태입니다.
뒤늦게 (2, 99)가 head가 되어서 큐에서 나왔을 땐, 쓸데없이 for문을 돌면서 자식 노드에 대한 검사를 또 하는 거죠. 이미 (2, 3)때 똑같은 작업을 한 상태이고, (2, 3)때 자식 노드에 대해 설정한 dist들은 (2, 99)때도 완벽히 똑같습니다. 이땐 굳이 for문을 돌릴 필요가 없죠. 물론 35번째 줄 if문에서 조건이 전부 false가 될 거라 아무 일도 안 하긴 하겠지만, 아무것도 안 하는데 for문을 괜히 한 번씩 돌아보는 것도 문제잖아요?
이렇듯 이미 큐에 (2, 99)가 있는데 똑같은 노드 번호이면서 더 낮은 비용의 (2, 3)이 큐에 들어오는 경우엔 (2, 99)가 head로 튀어나왔을 때 dist[2] != head.second인 상황이 발생하는 거죠.
그리고 그 상황엔 for문을 갈 필요가 없으니 continue 해서 넘어가는 것입니다.
'프로그래밍 > 안드로이드, 코틀린' 카테고리의 다른 글
| 백준 반례 찾는 방법 (코틀린) (0) | 2022.03.16 |
|---|---|
| 백준 1920번 코틀린 (0) | 2022.03.15 |
| 코틀린 DFS, BFS 코드 (0) | 2022.03.10 |
| 코틀린 String에서 특정 문자 개수 count (혹은 Int형 특정 숫자 개수) (0) | 2022.02.24 |
| 코틀린 IntArray와 Array<Int> 차이 (0) | 2022.02.24 |

